简介:
1.逻辑回归虽然名字叫做回归,但是它是一种分类算法。
2.逻辑回归是一种基于多元线性回归的算法,正因为如此,它是一种线性的分类算法。
决策树,神经网络等算法是非线性的算法。SVM本质是线性的算法,但是可以通过核函数升维变成非线性的算法。
3.逻辑回归就是在多元线性回归的基础之上吧结果缩放到0-1之间,缩放使用的函数是sigmoid函数
经过sigmoid缩放后的结果越接近于正1越是正例,越接近于0越是负例。根据0.5作为分界线。
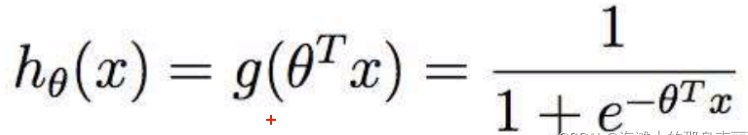
是最泛化的写法
代表的意思是多元线性回归经过g函数(对于逻辑回归来说就是sigmoid函数)的变化。
4.当我们以0.5作为分界时,就是要找sigmoid=0.5时theta的解

from sklearn.feature_selection import SelectFromModel
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
import numpy as np
def lr_test():
lbc_data = load_breast_cancer()
X = lbc_data.data
y = lbc_data.target
print(X.shape)
"""
max_iter迭代次数, 这里max_iter设置越大代表步长越小,设置越小代表步长越大。
当max_iter设置的过小,loss会还没有降到最低点前就停止迭代,那么训练完模型,sklearn会提示还没有达到最优点。
当然我们要考虑模型的泛化能力,如果max_iter设置过大,有可能会过拟合,虽然没有报红警告,但是测试集准确率并不高,
如果迭代完毕返现提示报红,但是训练集和测试集准确率都比较高,那么说明模型训练的还不错
C是正则项l2前面的权重,不过在sklearn中,参数C是加在mse前面,C越大代表泛化能力越弱,准确率越高。
"""
"""
multi_class
ovr代表处理二分类问题
multinomial代表处理多分类问题
auto是根据分类情况其他参数确定模型分离的分类问题类型,比如solver取值liblinear,auto会默认选择ovr,反之会选择multinomial
solver一共有5种选择,liblinear(只能用做二分类),lbfgs(拟牛顿法,在大型数据计算不快),newton-cg(牛顿法,在大型数据计算不快),sag(梯度下降,适合大型数据),saga
"""
"""
tol=1e-4代表最后两次loss的差值小于十的负四次方就停止迭代(连续判断十次)
"""
lr = LogisticRegression(penalty='l2', solver='liblinear', C=0.8, random_state=30, max_iter=100, multi_class='ovr')
# print(cross_val_score(lr, X, y, cv=10).mean())
# norm_order用l1范数进行进行筛选,模型会筛选掉l1范数后为0的特征
# sfm = SelectFromModel(lr, norm_order=1).fit_transform(X, y)
# print(sfm.shape)
# print(cross_val_score(lr, sfm, y, cv=10).mean())
threshold = np.linspace(0, abs(lr.fit(X, y).coef_).max(), 20)
lbc_scores = []
sfm_scores = []
k = 0
for i in threshold:
sfm = SelectFromModel(lr, threshold=i).fit_transform(X, y)
lbc_score = cross_val_score(lr, X, y, cv=5).mean()
sfm_score = cross_val_score(lr, sfm, y, cv=5).mean()
sfm_scores.append(sfm_score)
lbc_scores.append(lbc_score)
print(threshold[k], sfm.shape[1])
k += 1
plt.figure(figsize=(15, 5))
plt.plot(threshold, sfm_scores, label='feature selection')
plt.plot(threshold, lbc_scores, label='full')
plt.xticks(threshold)
plt.legend()
plt.show()
if __name__ == "__main__":
lr_test()
