一、介绍
1. 前言
春联,又称“春贴”、“门对”、“对联”,是过年时所贴的红色喜庆元素“年红”中一个种类。它以对仗工整、简洁精巧的文字描绘美好形象,抒发美好愿望,是中国特有的文学形式,是华人们过年的重要习俗。当人们在自己的家门口贴年红(春联、福字、窗花等)的时候,意味着过春节正式拉开序幕。

2、项目介绍:
本项目基于PaddleHub的对联生成模型ernie_tiny_couplet,使用的是paddlepaddle 2.x 框架,根据上联生成对联的下联。
ernie_gen_couplet框架:
ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。
此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。
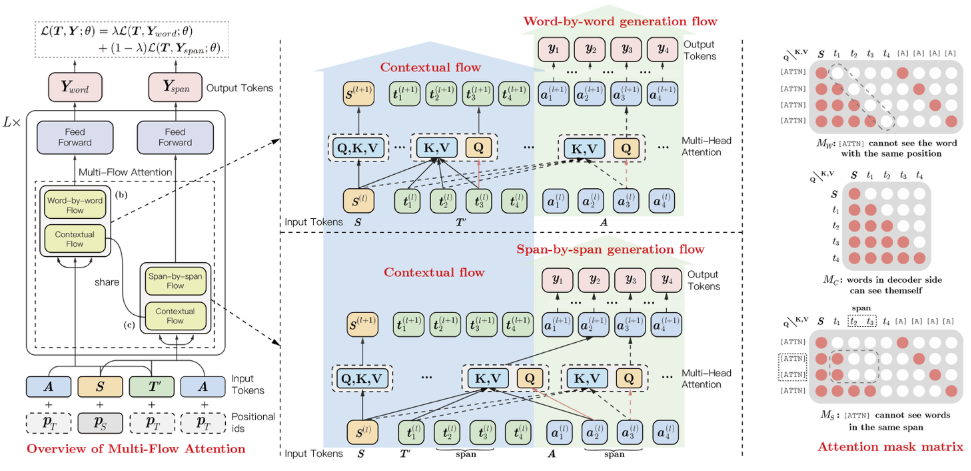
ernie_gen_couplet采用开源对联数据集进行微调,可用于生成下联。下图是模型结构:
ernie_tiny_couplet模型:
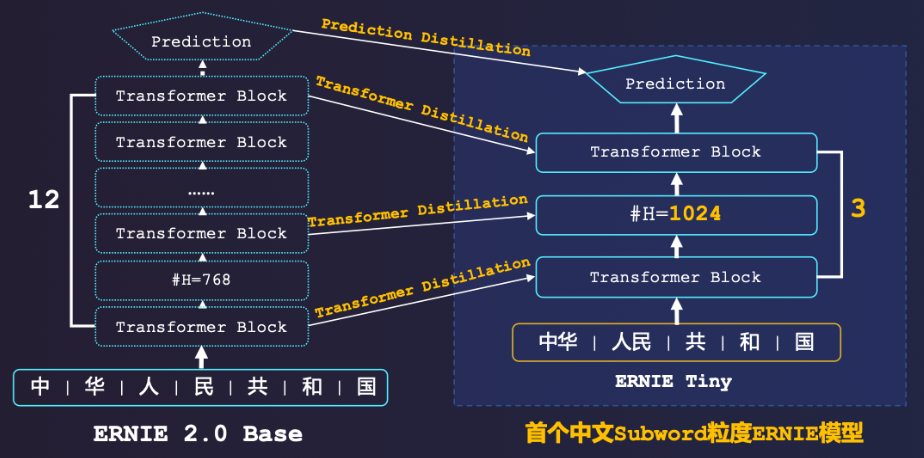
ernie_tiny_couplet是一个对联生成模型,它由ernie_tiny预训练模型经PaddleHubTextGenerationTask微调而来,仅支持预测,如需进一步微调请参考PaddleHub text_generation demo。
预训练模型转换成预测module的转换方式请参考Fine-tune保存的模型如何转化为一个PaddleHub Module。
下图是模型结构:
3. 基本要求
对联文字长短不一,短的仅一、两个字;长的可达几百字。对联形式多样,有正对、反对、流水对、联球对、集句对等。但不管何类对联,使用何种形式,都必须具备以下特点:
要字数相等,断句一致。除有意空出某字的位置以达到某种效果外,上下联字数必须相同,不多不少。
要平仄相合,音调和谐。传统习惯是「仄起平落」,即上联末句尾字用仄声,下联末句尾字用平声。
要词性相对,位置相同。一般称为「虚对虚,实对实」,就是名词对名词,动词对动词,形容词对形容词,数量词对数量词,副词对副词,而且相对的词必须在相同的位置上。
要内容相关,上下衔接。上下联的含义必须相互衔接,但又不能重复。
二、配置安装环境
- 平台: winodows10
- 编译器:PyCharm
conda create -n couplet python=3.8
conda activate couplet
pip install paddlepaddle-gpu==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple四、运行
1、创建执行脚本couplet.py,代码如下:
import paddlehub as hub
module = hub.Module(name="ernie_gen_couplet")
test_texts = ["春风又绿江南岸"]
results = module.generate(texts=test_texts, use_gpu=False, beam_width=5)
for result in results:
print(result)
效果

2、生成春联图片
import paddlehub as hub
import re
import io
from PIL import Image
import numpy as np
import requests
module = hub.Module(name="ernie_gen_couplet") # 加载模型
# ***************春 联 上 联***************
test_texts_a = ['一年四季春常在'] #可以通过修改 test_texts_a 中的内容,生成你想要的春联。
test_texts_bs = module.generate(texts=test_texts_a, use_gpu=True, beam_width=1)
test_texts_b = test_texts_bs[0]
# 获取汉字图片
def get_word(ch, quality):
"""
ch - 单个汉字或英文字母(仅支持大写)
quality - 单字分辨率,H-640像素,M-480像素,L-320像素
"""
fp = io.BytesIO(requests.post(url='http://xufive.sdysit.com/tk', data={'ch': ch}).content) # 只包含大约1500常用汉字
im = Image.open(fp)
w, h = im.size
if quality == 'M':
w, h = int(w * 0.75), int(0.75 * h)
elif quality == 'L':
w, h = int(w * 0.5), int(0.5 * h)
return im.resize((w, h))
# 生成春联背景图
def get_bg(quality):
return get_word('bg', quality)
# 生成春联
def write_couplets(text, HorV='V', quality='L', out_file=None):
"""
text - 春联内容,以空格断行
HorV - H-横排,V-竖排
quality - 单字分辨率,H-640像素,M-480像素,L-320像素
out_file - 输出文件名
"""
usize = {'H': (640, 23), 'M': (480, 18), 'L': (320, 12)}
bg_im = get_bg(quality)
text_list = [list(item) for item in text.split()]
rows = len(text_list)
cols = max([len(item) for item in text_list])
if HorV == 'V':
ow, oh = 40 + rows * usize[quality][0] + (rows - 1) * 10, 40 + cols * usize[quality][0]
else:
ow, oh = 40 + cols * usize[quality][0], 40 + rows * usize[quality][0] + (rows - 1) * 10
out_im = Image.new('RGBA', (ow, oh), '#f0f0f0')
for row in range(rows):
if HorV == 'V':
row_im = Image.new('RGBA', (usize[quality][0], cols * usize[quality][0]), 'white')
offset = (ow - (usize[quality][0] + 10) * (row + 1) - 10, 20)
else:
row_im = Image.new('RGBA', (cols * usize[quality][0], usize[quality][0]), 'white')
offset = (20, 20 + (usize[quality][0] + 10) * row)
for col, ch in enumerate(text_list[row]):
if HorV == 'V':
pos = (0, col * usize[quality][0])
else:
pos = (col * usize[quality][0], 0)
ch_im = get_word(ch, quality)
row_im.paste(bg_im, pos)
row_im.paste(ch_im, (pos[0] + usize[quality][1], pos[1] + usize[quality][1]), mask=ch_im)
out_im.paste(row_im, offset)
if out_file:
out_im.convert('RGB').save(out_file)
out_im.show()
# 开始写春联
text = test_texts_b,test_texts_a
text=re.sub('[^\u4e00-\u9fa5]+',' ',str(text))
write_couplets(text, HorV='V', quality='M', out_file='春联.jpg')
效果:


