github链接:https://github.com/Vision-CAIR/MiniGPT-4
一、项目介绍:
MiniGPT-4|使用高级大语言模型增强视觉语言理解
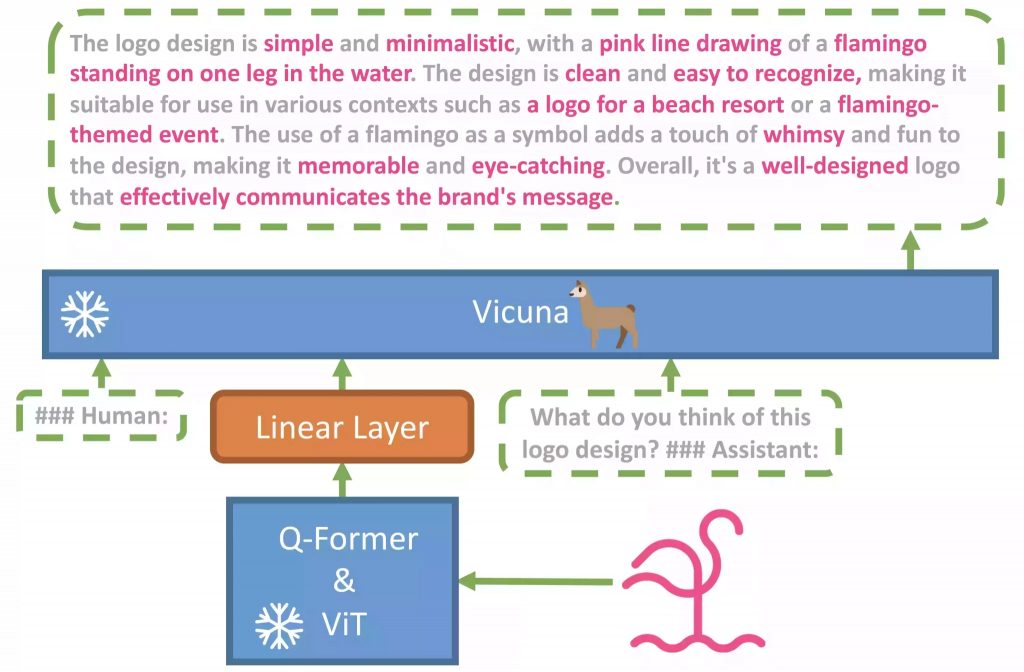
介绍
- MiniGPT-4仅使用一个投影层将来自BLIP-2的冻结视觉编码器与冻结的LLM,Vicuna对齐。
- 我们分两个阶段训练 MiniGPT-4。第一个传统的预训练阶段是使用 5 个 A10 在 4 小时内使用大约 100 万个对齐的图像文本对进行训练。在第一阶段之后,骆马能够理解图像。但骆马的生成能力受到严重影响。
- 为了解决这个问题并提高可用性,我们提出了一种新颖的方法,通过模型本身和 ChatGPT 一起创建高质量的图像文本对。在此基础上,我们创建了一个小的(总共3500对)但高质量的数据集。
- 第二个微调阶段在对话模板中对此数据集进行训练,以显着提高其生成可靠性和整体可用性。令我们惊讶的是,这个阶段的计算效率很高,使用单个 A7 只需要大约 100 分钟。
- MiniGPT-4 产生了许多新兴的视觉语言功能,类似于 GPT-4 中展示的功能。
GitHub
项目开源地址:Vision-CAIR/MiniGPT-4
二、环境安装
- 平台:windows 10
- 编译器:pycharm
- cuda 11.3
- cudnn 8.2.0.53
conda env create -p D:\\openai.wiki\\MiniGPT-4\\minigpt4 -f D:\\openai.wiki\\MiniGPT-4\\environment.yml三、执行代码
conda activate D:\\openai.wiki\\MiniGPT-4\\minigpt4模型相关
⚠️注意:自编译模型该项目的模型文件比较特殊,需要自行编译,官方因版权问题并没有直接提供可以直接使用的模型文件。需要自行下载两个模型进行编译,编译可能需要128GB内存,本站的电脑只有32GB内在,无法达到要求,请各位自行编译。
官方下载
Vicuna官方下载地址:lmsys/vicuna-13b-delta-v0 · Hugging Face
LLAMA-13B官方下载地址:LLaMA (huggingface.co)
MiniGPT-4官方下载地址:https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link
网盘下载
vicuna-13b-delta-v0:https://www.123pan.com/s/sKd9-fcJc.html
LLAMA-13B:https://www.123pan.com/s/sKd9-BcJc.html
MiniGPT-4:https://www.123pan.com/s/sKd9-acJc.html
Vicuna模型配置
需要注意的是,这并不是直接使用的工作权重,而是工作权重和 LLAMA-13B 原始权重之间的差异。(由于 LLAMA 的规定,我们无法分发 LLAMA 的权重。)
然后,您需要获取HuggingFace格式的原始LLAMA-13B权重,可以按照HuggingFace提供的说明或从互联网或本站获取。
当这两个权重准备好后,我们可以使用 Vicuna 团队提供的工具来创建真正的工作权重。首先,通过以下方式安装与v0版本的Vicuna兼容的库:
pip install git+https://github.com/lm-sys/FastChat.git@v0.1.10将下载后的两个模型分别移动至D:/openai.wiki/MiniGPT-4目录下新建Model文件夹,分别放入或新建如下路径文件
LLAMA-13B模型路径D:/openai.wiki/MiniGPT-4/Model/llama-13b-hf
vicuna-13b-delta-v0模型路径D:/openai.wiki/MiniGPT-4/Model/vicuna-13b-delta-v0
working-vicuna最终输出路径D:/openai.wiki/MiniGPT-4/Model/working-vicuna
最后,运行以下命令以创建最终的工作权重:
python -m fastchat.model.apply_delta --base D:/openai.wiki/MiniGPT-4/Model/llama-13b-hf/ --target D:/openai.wiki/MiniGPT-4/Model/weight/ --delta D:/openai.wiki/MiniGPT-4/Model/vicuna-13b-delta-v0/等待良久之后,将会在D:/openai.wiki/MiniGPT-4/Model/working-vicuna目录下生成已编译后的新权重文件。
vicuna_weights
├── config.json
├── generation_config.json
├── pytorch_model.bin.index.json
├── pytorch_model-00001-of-00003.bin
...修改D:\openai.wiki\MiniGPT-4\minigpt4\configs\models\minigpt4.yaml文件,将第16行的内容替换为你的模型路径。
model:
arch: mini_gpt4
# vit encoder
image_size: 224
drop_path_rate: 0
use_grad_checkpoint: False
vit_precision: "fp16"
freeze_vit: True
freeze_qformer: True
# Q-Former
num_query_token: 32
# Vicuna
llama_model: "D:/openai.wiki/MiniGPT-4/Model/working-vicuna"
# generation configs
prompt: ""
preprocess:
vis_processor:
train:
name: "blip2_image_train"
image_size: 224
eval:
name: "blip2_image_eval"
image_size: 224
text_processor:
train:
name: "blip_caption"
eval:
name: "blip_caption"MiniGPT-4模型配置
修改D:\openai.wiki\MiniGPT-4\eval_configs\minigpt4_eval.yaml文件,将第11行的内容替换为你的MiniGPT-4模型路径。
model:
arch: mini_gpt4
model_type: pretrain_vicuna
freeze_vit: True
freeze_qformer: True
max_txt_len: 160
end_sym: "###"
low_resource: True
prompt_path: "prompts/alignment.txt"
prompt_template: '###Human: {} ###Assistant: '
ckpt: '/path/to/pretrained/ckpt/'
datasets:
cc_sbu_align:
vis_processor:
train:
name: "blip2_image_eval"
image_size: 224
text_processor:
train:
name: "blip_caption"
run:
task: image_text_pretrain四、使用教程
启动MiniGPT-4的方法非常简单,按顺序执行如下代码即可。
激活MiniGPT-4的Conda虚拟环境
conda activate D:\\openai.wiki\\MiniGPT-4\\minigpt4
切换目录至MiniGPT-4项目路径
cd /d D:\\openai.wiki\\MiniGPT-4
执行行如命令,启动MiniGPT-4。
python demo.py –cfg-path eval_configs/minigpt4_eval.yaml
在这里,我们默认将 Vicuna 加载为 8 bit以节省一些 GPU 内存使用量。 此外,默认波束搜索宽度为 1。 在此设置下,演示花费大约 23G GPU 内存。 如果您有功率更强大的 GPU 和更大的 GPU 内存,则可以运行该模型在配置文件D:\\openai.wiki\\MiniGPT-4\\eval_configs\\minigpt4_eval.yaml中将low_resource设置为False并使用更大的波束搜索宽度,在 4 bit中。

