一、介绍:
前些日子比较火的换脸AI技术是Roop,但是Roop已经停止更新了,好像是因为团队成员用这个东西搞颜色吧。不知道为什么又搞了个FaceFusion,以后的更新也会围绕着FaceFusion啦。
不知道是不是心理作用,总感觉FaceFusion比Roop更加好用。
使用该软件,您可以将一段视频中的人脸替换成您选择的人脸,只需要一张所需人脸的图像,无需数据集和训练。
免责声明
在使用他人面部图像前,用户必须得到相关人士的同意,并在发布内容时不得隐瞒它是深度伪造。本站不对最终用户的恶意行为负责。
为了防止滥用,它内置了一个检查程序,防止该程序用于不当媒体。
项目仓库
GitHub:facefusion/facefusion
前置条件
在执行项目安装之前,我们还需要安装Git和Conda,还有FFMpeg,如果您的电脑还未安装这几款软件,请先根据本站所给出的教程安装。
Windows系统安装Git请参阅此文章:
http://dataddd.com/git%ef%bd%9cwindows%e5%ae%89%e8%a3%85%e6%95%99%e7%a8%8b/
Windows系统安装Conda请参阅此文章:
http://dataddd.com/anaconda%ef%bd%9cminiconda%ef%bd%9cwindows%e5%ae%89%e8%a3%85%e6%95%99%e7%a8%8b/
Windows系统安装FFMpeg请参阅此文章:
Visual Studio
在安装之前我们还需要下载Visual Studio
下载地址:Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器 (microsoft.com)
下载并安装Visual Studio 2022时,只需要勾选通过 Windows 平台开发项,然后点击安装,等待完成即可。
安装教程
如果您是初学者,对于命令行不太理解,那么请按下键盘上的Win键+R键后,在弹出的新窗口内输入CMD并按下回车,打开CMD窗口,按顺序执行如下的每一条命令。
首先我们需要确认一个工作目录,用来存放facefusion的相关环境依赖文件。本站所选择的目录为D盘的根目录下dataddd文件夹,完整路径为:D:\。dataddd
检测D盘是否在dataddd
if not exist D:dataddd mkdir D:\dataddd强制切换工作路径为D盘的openai.wiki\facefusion文件夹。
cd /d D:\dataddd拉取Github仓库文件夹,将下载至dataddd文件夹。
git clone https://github.com/facefusion/facefusion.git如果您无法完成此步骤,执行后报错或者无法下载,可以下载该文件将其解压至D:\即可。dataddd
环境部署
在CMD中执行如下命令,强制切换至facefusion的项目目录。
cd /d D:\dataddd\facefusion在CMD中执行下面的命令行,创建Conda虚拟环境至该项目的目录中,方便日后重装系统也能够正常使用,无需重新部署环境。
conda create -y -p D:\dataddd\facefusion\ENV python=3.10初始化Conda环境,避免后续可能报错。
conda init cmd.exe激活已创建的Conda环境,这样我们可以将我们后续所需要的所有环境依赖都安装至此环境下。
conda activate D:\dataddd\facefusion\ENV执行如下命令,安装访项目的相关依赖库。
pip install -r requirements.txt图形加速
其实目前为止,你已经可以正常运行了,但速度会非常慢。如果您有一张好的GPU,你可以按照此处的教程安装GPU加速。
以下是针对各显卡安装图形加速的方法,请根据自身系统进行选择。
在你确认自己的显卡型号之后,在CMD中按顺序执行如下代码即可。
注意:最后一行是启动方式,如果你希望以CPU方式运行,那么可以不添加任何参数,直接运行python run.py,假如你想使用CUDA加速,那就执行python run.py --execution-providers cuda。
英伟达
- http://dataddd.com/cuda%ef%bd%9cwindows%e7%b3%bb%e7%bb%9f%e5%ae%89%e8%a3%85%e6%95%99%e7%a8%8b%e5%85%a8%e6%94%bb%e7%95%a5/
- http://dataddd.com/cudnn%ef%bd%9cwindows%e7%b3%bb%e7%bb%9f%e5%ae%89%e8%a3%85%e6%95%99%e7%a8%8b/
pip uninstall onnxruntime onnxruntime-gpupip install onnxruntime-gpu==1.15.1python run.py --execution-providers cuda
AMD
pip uninstall onnxruntime onnxruntime-directmlpip install onnxruntime-directml==1.15.1python run.py --execution-providers dml
苹果电脑|M芯片
pip uninstall onnxruntime onnxruntime-siliconpip install onnxruntime-silicon==1.13.1python run.py --execution-providers coreml
苹果电脑|非M芯片
pip uninstall onnxruntime onnxruntime-coremlpip install onnxruntime-coreml==1.13.1python run.py --execution-providers coreml
英特尔
pip uninstall onnxruntime onnxruntime-openvinopip install onnxruntime-openvino==1.15.0python run.py --execution-providers openvino
二、模型下载
参见百度链接
该模型默认路径为%USERPROFILE%,我们可以通过在CMD中执行下面的代码,将会自动打开模型存放的对应目录,也就是你的用户文档。
start %USERPROFILE%将我们下载完成的模型文件解压缩,你将会得到两个名为.insightface和.opennsfw2的文件夹,将其移动到你自动打开的这个文件夹内即可。
运行方式
在以后每次运行该项目时,只需要先激活Conda环境,然后运行启动文件即可。
在CMD中执行如下命令,强制切换至facefusion的项目目录。
cd /d D:\dataddd\facefusion激活已创建的Conda环境,这样我们可以将我们后续所需要的所有环境依赖都安装至此环境下。
conda activate D:\dataddd\facefusion\ENV执行如下代码,运行facefusion的UI界面。
python run.py使用教程
当我们完成上述步骤中执行python run.py代码后,你将会在CMD窗口中看到如下内容。
(D:\dataddd\facefusion\ENV) D:\dataddd\facefusion>python run.py
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.我们此时在浏览器中打开所给出的网址http://127.0.0.1:7860,即可访问该项目的界面。
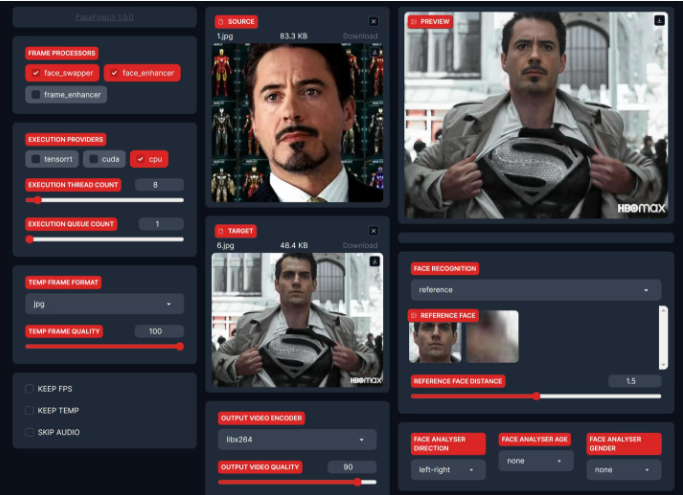
以下是关于界面的各功能描述:
- FRAME PROCESSORS(帧处理器):
face_swapper(脸部交换): 一种在图像或视频中交换脸部的算法,类似于深度伪造技术。face_enhancer(脸部增强): 一种增强或改进图像或视频中脸部质量的算法。frame_enhancer(帧增强): 一种增强或改进整个图像或视频帧的算法。
- EXECUTION PROVIDERS(运算方式):
- 用于选择你想选用的推理方式,比如你可以选择使用CUDA加速,如果你不懂这是什么,可以先选择CUDA看看能不能运行成功,不成功就切换为CPU。
tensorrt: NVIDIA TensorRT 是一个用于高性能深度学习推理的平台,针对 NVIDIA GPUs 进行了优化。cuda: CUDA 是 NVIDIA 开发的用于 GPU 上的通用计算的并行计算平台和编程模型。cpu(中央处理器): 使用计算机的中央处理器进行执行,而不是使用 GPU。
- EXECUTION THREAD COUNT(执行线程数):
8: 指的是用于执行算法的线程或并行进程的数量。更多的线程通常意味着更快的处理,但最佳数量可能取决于硬件。
- EXECUTION QUEUE COUNT(执行队列数):
1: 指的是一次可以排队执行的任务或作业的数量。
- TEMP FRAME FORMAT(临时帧格式):
jpg: 指的是在处理过程中用于保存临时帧的格式。JPEG (或 JPG) 是一种常见的图像格式。
- TEMP FRAME QUALITY(临时帧质量):
100: 对于 JPEG 格式的压缩质量,其中 100 是最高质量(最少压缩)。更高的质量通常意味着更大的文件大小。
- KEEP FPS(保持帧率):
- 确保视频的每秒帧数(FPS)在处理过程中保持一致或不变。
- KEEP TEMP(保持临时文件):
- 在处理完成后是否保留临时文件(如中间处理帧)的标志。
- SKIP AUDIO(跳过音频):
- 对于视频处理,此标志可能用于决定是否处理或忽略视频的音轨。
- SOURCE
- 上传图像区域
- TARGET
- 上传视频区域
- OUTPUT VIDEO ENCODER(输出视频编码器)
- 用于选择视频编码方式,保持默认即可,
- OUTPUT VIDEO QUALITY(输出视频质量)
- 建议设置为100%
- OUTPUT
- 最终渲染视频呈现区域
- PREVIEW
- 效果预览区域,可以快速查看生成后的效果预览。
- FACE RECOGNITION
- 人脸识别区域,用于识别预览区域的人像提取。如果你有多张人脸,可以在这里选择目标人脸。
- FACE ANALYSER DIRECTION(人脸分析:方向)
- FACE ANALYSER AGE(人脸分析:年龄)
- FACE ANALYSER GENDER(人脸分析:性别)
参数很多?没关系,我们需要做的其实非常简单,那就是先点击SOURCE区域,这会自动弹出一个文件选择的窗口,我们选择一张人物图片即可,这张图片将会做为替换的素材。
然后点击TARGET区域,这会自动弹出一个文件选择的窗口,我们选择一个包含人物的视频,这个视频为被替换面部的视频。
最后我们点击START按钮,即可自动开始处理视频了。
命令行参数
以下是额外的命令行参数,一般不需要调整,忽略此部分内容即可。
python run.py [选项]
-h, --help 显示此帮助信息并退出
-s SOURCE_PATH, --source SOURCE_PATH 选择一个源图片
-t TARGET_PATH, --target TARGET_PATH 选择一个目标图片或视频
-o OUTPUT_PATH, --output OUTPUT_PATH 指定输出文件或目录
--frame-processors FRAME_PROCESSORS [FRAME_PROCESSORS ...] 从可用的帧处理器中选择 (选择范围: face_enhancer, face_swapper, frame_enhancer, ...)
--ui-layouts UI_LAYOUTS [UI_LAYOUTS ...] 从可用的UI布局中选择 (选择范围: benchmark, default, ...)
--keep-fps 保持目标的帧速率 (fps)
--keep-temp 处理后保留临时帧
--skip-audio 从目标中删除音频
--face-recognition {reference,many} 指定面部识别的方法
--face-analyser-direction {left-right,right-left,top-bottom,bottom-top,small-large,large-small} 指定用于面部分析的方向
--face-analyser-age {child,teen,adult,senior} 指定用于面部分析的年龄
--face-analyser-gender {male,female} 指定用于面部分析的性别
--reference-face-position REFERENCE_FACE_POSITION 指定参考脸的位置
--reference-face-distance REFERENCE_FACE_DISTANCE 指定参考脸与目标脸之间的距离
--reference-frame-number REFERENCE_FRAME_NUMBER 指定参考帧的数量
--trim-frame-start TRIM_FRAME_START 指定提取的起始帧
--trim-frame-end TRIM_FRAME_END 指定提取的结束帧
--temp-frame-format {jpg,png} 指定用于帧提取的图像格式
--temp-frame-quality [0-100] 指定用于帧提取的图像质量
--output-video-encoder {libx264,libx265,libvpx-vp9,h264_nvenc,hevc_nvenc} 指定用于输出视频的编码器
--output-video-quality [0-100] 指定输出视频的质量
--max-memory MAX_MEMORY 指定要使用的最大RAM数量 (单位: gb)
--execution-providers {cpu} [{cpu} ...] 从可用的执行提供者中选择 (选择范围: cpu, ...)
--execution-thread-count EXECUTION_THREAD_COUNT 指定执行线程的数量
--execution-queue-count EXECUTION_QUEUE_COUNT 指定执行查询的数量
-v, --version 显示程序的版本号并退出效果示例
换脸的测试过程中,站长尝试找了一些女网红的素材,好像现在的女网红长的都差不多,换脸之后也看不出来什么效果,于是……对不起了Shy哥,就用站长最喜欢的LOL选手吧。


