一、介绍

该模型全称为cv_gpen_image-portrait-enhancement,输入一张包含人像的图像,算法会对图像中的每一个检测到的人像做修复和增强,对图像中的非人像区域采用RealESRNet做两倍的超分辨率,最终返回修复后的完整图像。
GPEN将预训练好的StyleGAN2网络作为decoder嵌入到人像修复模型中,并通过finetune的方式最终实现修复功能,在多项指标上达到行业领先的效果。
适用范围
本模型适用范围较广,给定任意的包含人像的图片,在设备性能允许的情况下,都能输出修复后的效果图。
如何使用
在ModelScope框架上,提供任意图片,即可以通过简单的Pipeline调用来使用人像修复模型。
前置条件
在执行项目安装之前,我们还需要安装Git和Conda,如果您的电脑还未安装这两个软件,请先根据本站所给出的教程安装。
Windows系统安装Git请参阅此文章:
http://dataddd.com/git%ef%bd%9cwindows%e5%ae%89%e8%a3%85%e6%95%99%e7%a8%8b/
Windows系统安装Conda请参阅此文章:
http://dataddd.com/anaconda%ef%bd%9cminiconda%ef%bd%9cwindows%e5%ae%89%e8%a3%85%e6%95%99%e7%a8%8b/
二、安装教程
如果您是初学者,对于命令行不太理解,那么请按下键盘上的Win键+R键后,在弹出的新窗口内输入CMD并按下回车,打开CMD窗口,按顺序执行如下的每一条命令。
首先我们需要确认一个工作目录,用来存放cv_gpen_image-portrait-enhancement的相关环境依赖文件。本站所选择的目录为D盘的根目录下dataddd文件夹,完整路径为:D:\。dataddd
检测D盘是否在dataddd目录下有没有cv_gpen_image-portrait-enhancement文件夹,没有则创建该文件夹。
if not exist D:\dataddd\cv_gpen_image-portrait-enhancement mkdir D:\dataddd\cv_gpen_image-portrait-enhancement强制切换工作路径为D盘的dataddd\cv_gpen_image-portrait-enhancement
cd /d D:\dataddd\cv_gpen_image-portrait-enhancement环境部署
在CMD中执行下面的命令行,创建Conda虚拟环境至该项目的目录中,方便日后重装系统也能够正常使用,无需重新部署环境。
conda create -y -p D:\dataddd\cv_gpen_image-portrait-enhancement\ENV python=3.7初始化Conda环境,避免后续可能报错。
conda init cmd.exe激活已创建的Conda环境,这样我们可以将我们后续所需要的所有环境依赖都安装至此环境下。
conda activate D:\dataddd\cv_gpen_image-portrait-enhancement\ENV执行如下命令,安装阿里达摩院相关依赖。
pip install modelscope -i https://mirror.baidu.com/pypi/simple执行如下命令,安装CV2依赖库。
pip install opencv-python -i https://mirror.baidu.com/pypi/simple执行如下命令,安装torch依赖。
pip3 install torch torchvision torchaudio -i https://mirror.baidu.com/pypi/simple此时我们还需要安装一个scikit-image库,执行如下代码即可。
pip install scikit-image -i https://mirror.baidu.com/pypi/simple三、模型下载
在你首次运行生成代码时,将会自动下载模型,因为下载方式是国内直连,所以下载速度还是挺快的,毕竟是阿里提供的服务。
如果你想找到模型的存在位置,可以在运行中执行以下代码,这将会自动打开ModelScope的各项目缓存目录,模型就在这些目录内。
%USERPROFILE%\.cache\modelscope\hub\damo\cv_gpen_image-portrait-enhancement如果你不希望自动下载,而是通过国内网盘的方式,本站也提供了模型的网盘下载地址。
链接:https://pan.baidu.com/s/1hqzg6pBVITsiETA5vg0YLg?pwd=cct6
提取码:cct6
–来自百度网盘超级会员V4的分享
四、使用教程
此模型官方并未给出一个详细的脚本,本站写了一个简单的Python脚本,使用parcharm运行该Python脚本即可。在运行该脚本之前,请先对以下Python脚本中的名称|格式|路径根据自身情况进行修改。
注意:使用parcharm执行该脚本时,pycharm会提示您选择一个Python环境,此时您可以选择路径为D:\dataddd\cv_gpen_image-portrait-enhancement\ENV的Python环境,这就是我们刚刚使用Conda所生成的虚拟环境。
import cv2
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 原图名称
resultIMGName = '图像名称'
# 原图格式
resultIMGFormat = '.jpg'
# 原图路径
resultIMGPath = 'D:\dataddd\cv_gpen_image-portrait-enhancement'
# 输出图像名称
outputIMGName = '图像名称'
# 输出格式 | 尽量不要改
outputFormat = '.png'
# 输出路径
outputIMGPath = 'D:\dataddd\cv_gpen_image-portrait-enhancement'
# 下面的内容尽量不要改动
print (('原图路径:%s/%s%s'%(resultIMGPath,resultIMGName,resultIMGFormat)).replace('\\', '/'))
p = pipeline(Tasks.image_portrait_enhancement, model='damo/cv_gpen_image-portrait-enhancement')
result = p(('%s/%s%s'%(resultIMGPath,resultIMGName,resultIMGFormat)).replace('\\', '/'))
output_path = ('%s/%s%s'%(outputIMGPath,outputIMGName,outputFormat)).replace('\\', '/')
print (('输出路径:%s/%s%s'%(outputIMGPath,outputIMGName,resultIMGFormat)).replace('\\', '/'))
cv2.imwrite(output_path, result['output_img'])
print ('输出完成')五、效果示例
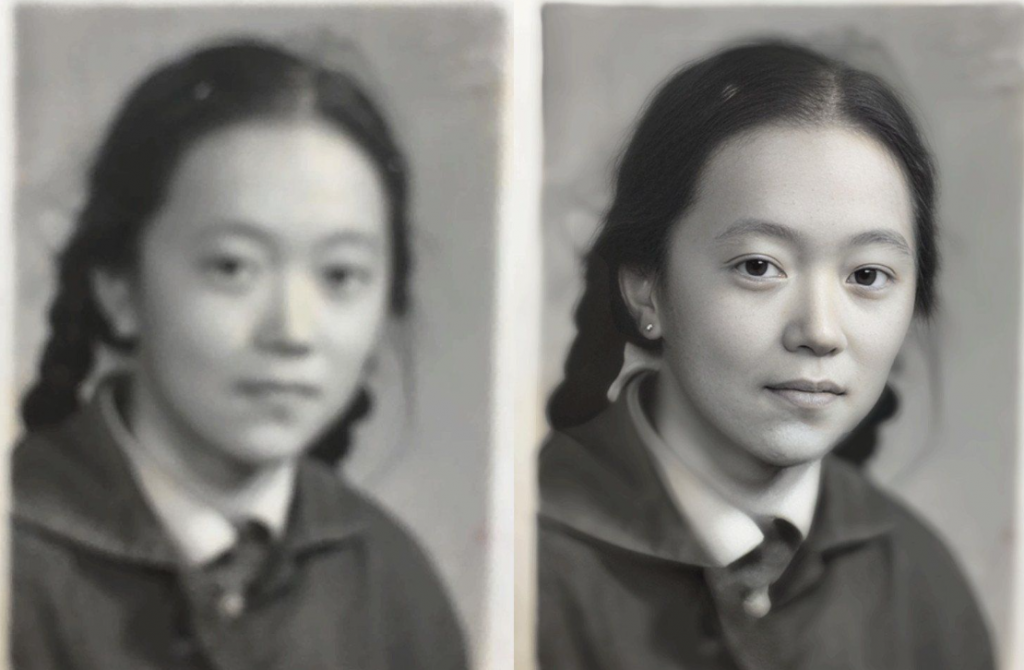
下面是一些图像使用效果示例,本站通过对多种使用环境进行对比发现,该模型对于人脸大部照效果较好,但是对于动物和远景等情况下所修复的效果较为一般。
模型局限性以及可能的偏差
- 目前提供的模型只支持512×512分辨率的输入,如果输入人脸分辨率或清晰度高于此,使用本模型可能会导致生成降质效果。
- 真实图片的降质很复杂,本算法使用模拟降质数据训练,可能存在处理不好的case。
- 本算法可能存在色偏等瑕疵现象。
训练数据
训练数据为FFHQ公开数据集。本算法采用监督式的训练,因此需要事先准备好高质-低质的数据对,推荐使用RealESRGAN、BSRGAN等降质方式进行低质数据生成。
微调流程
提供训练数据对的读取地址,设置好需要的分辨率版本(推荐512×512),调整生成器和判别器的学习率以及总epoch数,即可开始训练。
预处理
需要使用降质模型对FFHQ高清人像数据做降质,得到相对应的低质图片。
模型训练代码
import os
import tempfile
from modelscope.metainfo import Trainers
from modelscope.msdatasets import MsDataset
from modelscope.msdatasets.task_datasets.image_portrait_enhancement import \
ImagePortraitEnhancementDataset
from modelscope.trainers import build_trainer
from modelscope.utils.constant import DownloadMode
tmp_dir = tempfile.TemporaryDirectory().name
if not os.path.exists(tmp_dir):
os.makedirs(tmp_dir)
model_id = 'damo/cv_gpen_image-portrait-enhancement'
dataset_train = MsDataset.load(
'image-portrait-enhancement-dataset',
namespace='modelscope',
subset_name='default',
split='train',
download_mode=DownloadMode.REUSE_DATASET_IF_EXISTS)._hf_ds
dataset_val = MsDataset.load(
'image-portrait-enhancement-dataset',
namespace='modelscope',
subset_name='default',
split='validation',
download_mode=DownloadMode.REUSE_DATASET_IF_EXISTS)._hf_ds
dataset_train = ImagePortraitEnhancementDataset(
dataset_train, is_train=True)
dataset_val = ImagePortraitEnhancementDataset(
dataset_val, is_train=False)
kwargs = dict(
model=model_id,
train_dataset=dataset_train,
eval_dataset=dataset_val,
device='gpu',
work_dir=tmp_dir)
trainer = build_trainer(
name=Trainers.image_portrait_enhancement, default_args=kwargs)
trainer.train()数据评估及结果
| Metric | Value |
| FID | 31.72 |
| PSNR | 20.80 |
| LPIPS | 0.346 |
相关论文以及引用信息
@inproceedings{yang2021gpen,
title={GAN Prior Embedded Network for Blind Face Restoration in the Wild},
author={Tao Yang, Peiran Ren, Xuansong Xie, and Lei Zhang},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2021}
}
