一、项目介绍:
一、OCR概念及发展
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,经过检测暗、亮的模式肯定其形状,而后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并经过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提升识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也随之产生。
简单来说,OCR识别就是光学文字识别,是指通过图像处理和模式识别技术对光学的字符进行识别。**它是计算机视觉研究领域的分支之一,是计算机科学的重要组成部分。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。二、OCR发展

OCR的概念是在1929年由德国科学家Tausheck最早提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最先对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以一样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局做区域分信的做业;也所以至今邮政编码一直是各国所倡导的地址书写方式。
20世纪70年代初,日本的学者开始研究汉字识别,并作了大量的工做。中国在OCR技术方面的研究工做起步较晚,在70年代才开始对数字、英文字母及符号的识别进行研究,70年代末开始进行汉字识别的研究,到1986年,我国提出“863”高新科技研究计划,汉字识别的研究进入一个实质性的阶段,清华大学的丁晓青教授和中科院分别开发研究,相继推出了中文OCR产品,现为中国最领先汉字OCR技术。早期的OCR软件,因为识别率及产品化等多方面的因素,未能达到实际要求。同时,因为硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。进入20世纪90年代之后,随着平台式扫描仪的普遍应用,以及我国信息自动化和办公自动化的普及,大大推进了OCR技术的进一步发展,使OCR的识别正确率、识别速度知足了广大用户的要求。
三、OCR的应用场景
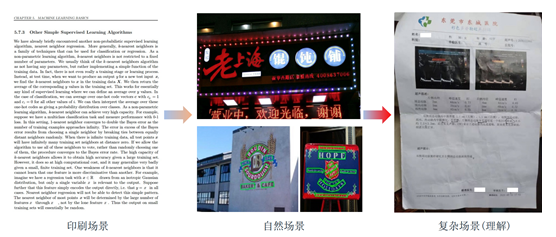
根据OCR的应用场景而言,我们可以大致分成识别特定场景下的专用OCR以及识别多种场景下的通用OCR。就前者而言,证件识别以及车牌识别就是专用OCR的典型案例。针对特定场景进行设计、优化以达到最好的特定场景下的效果展示。那通用的OCR就是使用在更多、更复杂的场景下,拥有比较好的泛性。在这个过程中由于场景的不确定性,比如:图片背景极其丰富、亮度不均衡、光照不均衡、残缺遮挡、文字扭曲、字体多样等等问题,会带来极大的挑战。文档文字识别:可以将图书馆、报社、博物馆、档案馆等的纸质版图书、报纸、杂志、历史文献档案资料等进行电子化管理,实现精准地保存文献资料。
自然场景文字识别:识别自然场景图像中的文字信息如车牌、广告干词、路牌等信息。对车辆进行识别可以实现停车场收费管理、交通流量控制指标测量、车辆定位、防盗、高速公路超速自动化监管等功能。
票据文字识别:可以对增值税发票、报销单、车票等不同格式的票据进行文字识别,可以避免财务人员手动输入大量票据信息,如今已广泛应用于财务管理、银行、金融等众多领域。。
证件识别:可以快速识别身份证、银行卡、驾驶证等卡证类信息,将证件文字信息直接转换为可编辑文本,可以大大提高工作效率、减少人工成本、还可以实时进行相关人员的身份核验,以便安全管理。
四、OCR的技术路线
典型的OCR技术路线如下图所示:

其中OCR识别的关键路径在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。
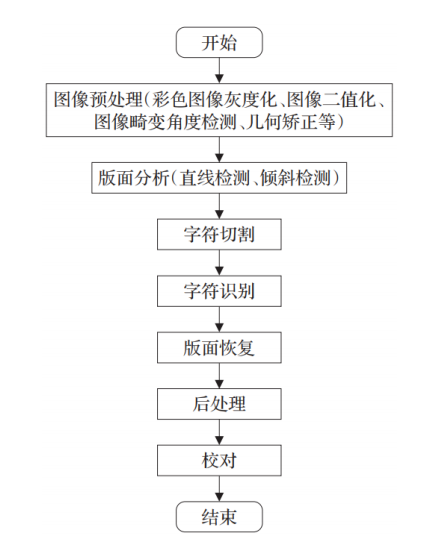
1.传统OCR技术流程:
1、水平投影垂直投影
2、模板匹配
3、查找轮廓findcontours
传统的光学字符识别过程为:图像预处理(彩色图像灰度化、二值化处理、图像变化角度检测、矫正处理等)、版面划分(直线检测、倾斜检测)、字符定位切分、字符识别、版面恢复、后处理、校对等。
2.深度学习OCR技术流程:
深度学习图像文字识别流程包括:输入图像、深度学习文字区域检测、预处理、特征提取、深度学习识别器、深度学习后处理等。

现有多数深度学习识别算法具体流程包括图像校正、特征提取、序列预测等模块,流程如图所示:

二、环境安装
- 显卡:3060ti
- 平台:windows 10
- 编译器:pycharm
- cuda 11.3
- cudnn 8.2.0.53
conda create -n modelscope python=3.7
conda activate modelscope
pip3 install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade tensorflow-gpu==1.15
pip install "modelscope[cv]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install protobuf==3.20.0三、执行代码
创建main.py
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import cv2
ocr_recognition = pipeline(Tasks.ocr_recognition, model='damo/cv_convnextTiny_ocr-recognition-general_damo')
### 使用url
img_url = 'http://duguang-labelling.oss-cn-shanghai.aliyuncs.com/mass_img_tmp_20220922/ocr_recognition.jpg'
result = ocr_recognition(img_url)
print(result)
### 使用图像文件
### 请准备好名为'ocr_recognition.jpg'的图像文件
# img_path = 'ocr_recognition.jpg'
# img = cv2.imread(img_path)
# result = ocr_recognition(img)
# print(result)四、效果展示



