一、介绍:
GitHub:aigc-apps/sd-webui-EasyPhoto: 📷 EasyPhoto

table Diffusion WebUI扩展插件EasyPhoto,翻译中文为简单照片。最近通过AI生成照片的一个APP很火,叫做妙鸭相机,通过上传几张你的个人照片就可以训练出角色模型,然后用户可以自由生成各种照片。可这有两个缺点,毕竟要上传个人照片到别人的服务器,而且妙鸭相机官方对于用户安全隐私的协议定义模糊,已经导致很多用户不满,上传后的照片使用权居然归官方所有。其二就是需要收费,对于量大的用户来说也是一个痛点。而站长在体验了EasyPhoto之后认为,这真的可以完美取代妙鸭相机,有过之而无不及,大部分参数都可以自定义,可用性极强,训练也极其简单。

二、下载模型
快捷安装
这种方式最为简单,下载后直接解压该文件,你将会得到一个名为sd-webui-EasyPhoto的文件夹,将其移动至.\stable-diffusion-webui\extensions目录内即可完成安装。
在线安装
此方法适用于魔法环境没有问题的朋友,可以通过在线安装的方式一键安装,非常方便。
打开Stable Diffusion的扩展界面后,点击从网址安装按钮,然后在扩展的git仓库网址输入框中粘贴如下网址,最后点击安装按钮即可,然后等待安装脚本自动执行。
https://github.com/aigc-apps/sd-webui-EasyPhoto.git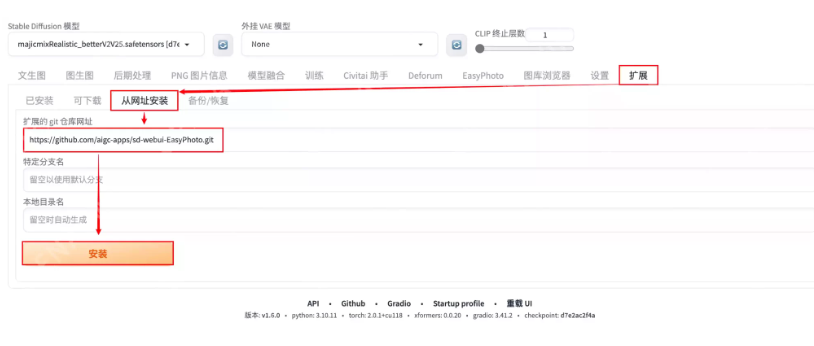
这可能需要等待几分钟,不要刷新或关闭网页。安装完成后点击页面最下方的重载UI按钮,UI重新启动后就可以在主菜单中看到EasyPhoto选项卡。
其它依赖
本插件还依赖于阿里的魔塔和huggingface的一些模型,如果你的魔法网络环境没有问题,那么你可以直接正常使用,该插件会自动下载相关内容。
但如果你的魔法网络存在问题,可以使用本站所提供的环境依赖包,关于该依赖的详细安装方式如下。
该插件的辅助模型默认路径为%USERPROFILE%\.cache,如果你是初次使用,可能不存在此路径,可以在CMD中执行如下代码判断该路径是否存在,如果不存在则自动创建。
if not exist %USERPROFILE%\.cache mkdir %USERPROFILE%\.cache执行完上面的代码之后,我们可以通过在CMD中执行下面的代码,自动打开模型目录。
start %USERPROFILE%\.cache将我们下载完成的模型文件解压缩,你将会得到两个文件夹,名称分别为huggingface和modelscope,移动至刚刚打开的文件夹(.cache)下即可。
三、使用教程
基础设置
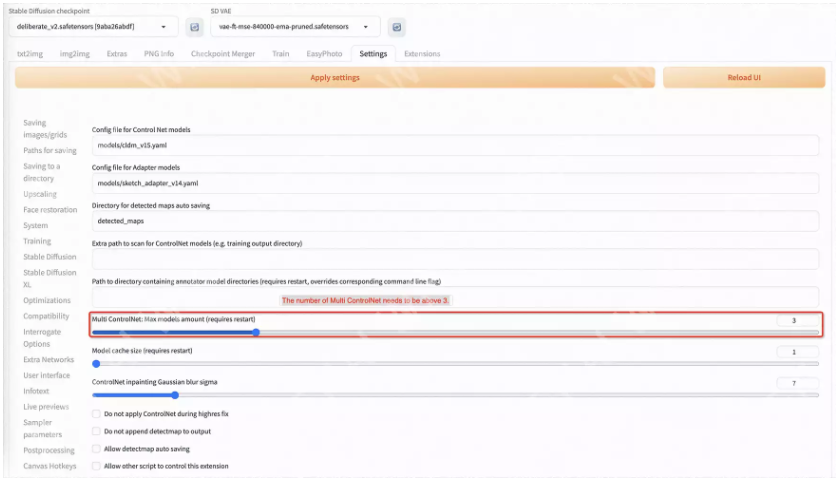
在使用此插件功能之前,我们还需要设置一下Controlnet。
我们至少需要三个Controlnets用于推理。因此,您需要设置Multi ControlNet: Max models amount (requires restart)。
模型训练
以下是程序的主界面,站长来讲解一下基础功能。
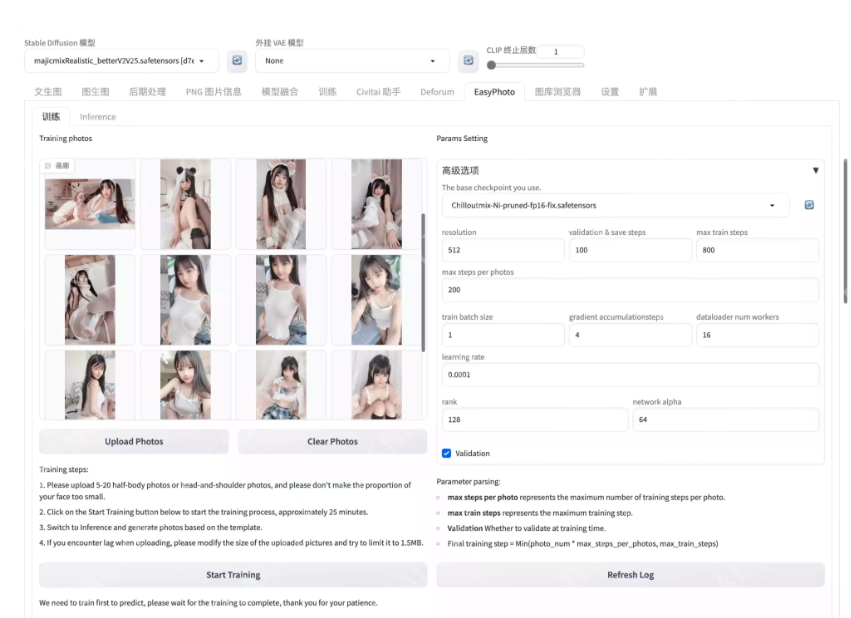

在开始即用之前,我们需要训练一个自己的角色模型,方便以后生成的图像都使用该模型,来确定角色的形象可以与所需要的人物一致。
我们点击Upload Photos按钮,上传5张至20张之间的同一个角色照片,比如站长本次使用的是樱景宁宁写真图,共计20张图片。
在右侧The base checkpoint you use.选择基础模型,也就是你希望训练模型时使用哪个模型做为训练时的基础Base,这很重要,这关乎于以后的出图风格。
如果要设置参数,以下是每个参数的解析:
| 参数名 | 含义 |
|---|---|
| resolution | 训练时喂入网络的图片大小,默认值为512。 |
| validation & save steps | 验证图片与保存中间权重的steps数,默认值为100,代表每100步验证一次图片并保存权重。 |
| max train steps | 最大训练步数,默认值为800。 |
| max steps per photos | 每张图片的最大训练次数,默认为200。 |
| train batch size | 训练的批次大小,默认值为1。 |
| gradient accumulationsteps | 是否进行梯度累计,默认值为4,结合train batch size来看,每个Step相当于喂入四张图片。 |
| dataloader num workers | 数据加载的works数量,windows下不生效,因为设置了会报错,Linux正常设置。 |
| learning rate | 训练Lora的学习率,默认为1e-4。 |
| rank Lora | 权重的特征长度,默认为128。 |
| network alpha | Lora训练的正则化参数,一般为rank的二分之一,默认为64。 |
在你设置完所有参数后,点击Start Training按钮,即可开始训练。此时网页会自动弹出一个窗口,让你输入一个名字,也就是角色的ID,方便让你知道以后应该选用哪个模型做为你的角色。随便输入,只要你能记得这是谁就好。
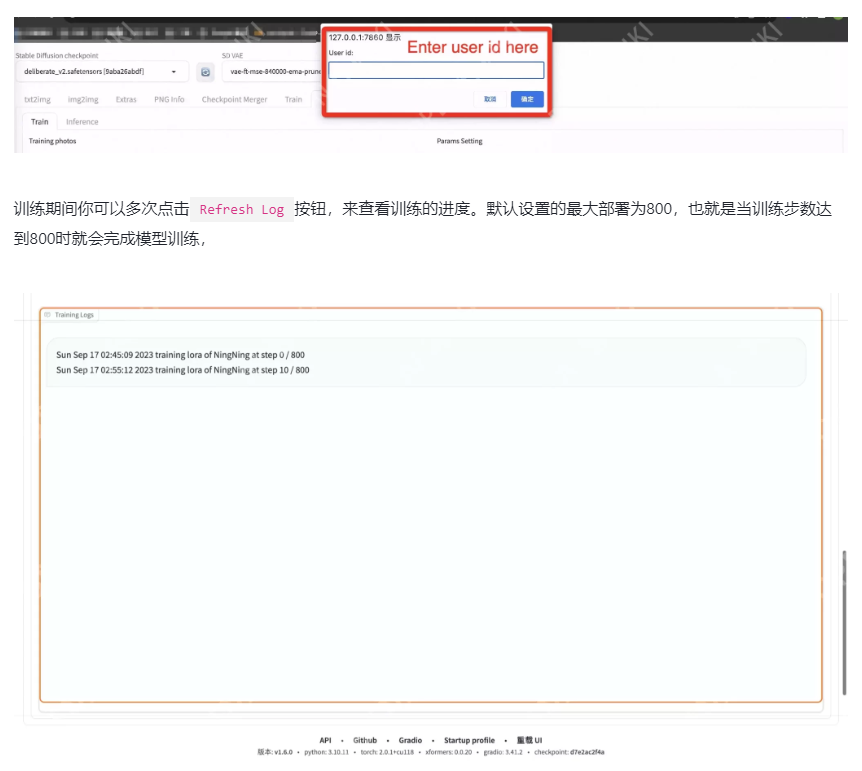
训练期间你可以多次点击Refresh Log按钮,来查看训练的进度。默认设置的最大部署为800,也就是当训练步数达到800时就会完成模型训练,
其实全部保持默认,训练后的效果也还不错。站长2080TI的显卡,20张超大原图分辨率图像的训练时间为5个小时左右,如果你的图像并不大,经过裁切之后可以大幅缩短训练时间。
图像生成
模型训练完成之后,我们可以来到Inference选项卡,里面内置了一些模板,你可以直接点击一张照片模板,然后在下面选择对应的基础模型和你训练的模型ID,比如本站设置训练樱景宁宁的角色ID为NN,那么在User id (The User id you provide while training)内你就可以选择为NN的模型,如果你没有看到该模型,可以点击🔄按钮刷新模型列表,这将会自动查找最新模型。
四、运行
python face_vilify.py
五、效果展示


